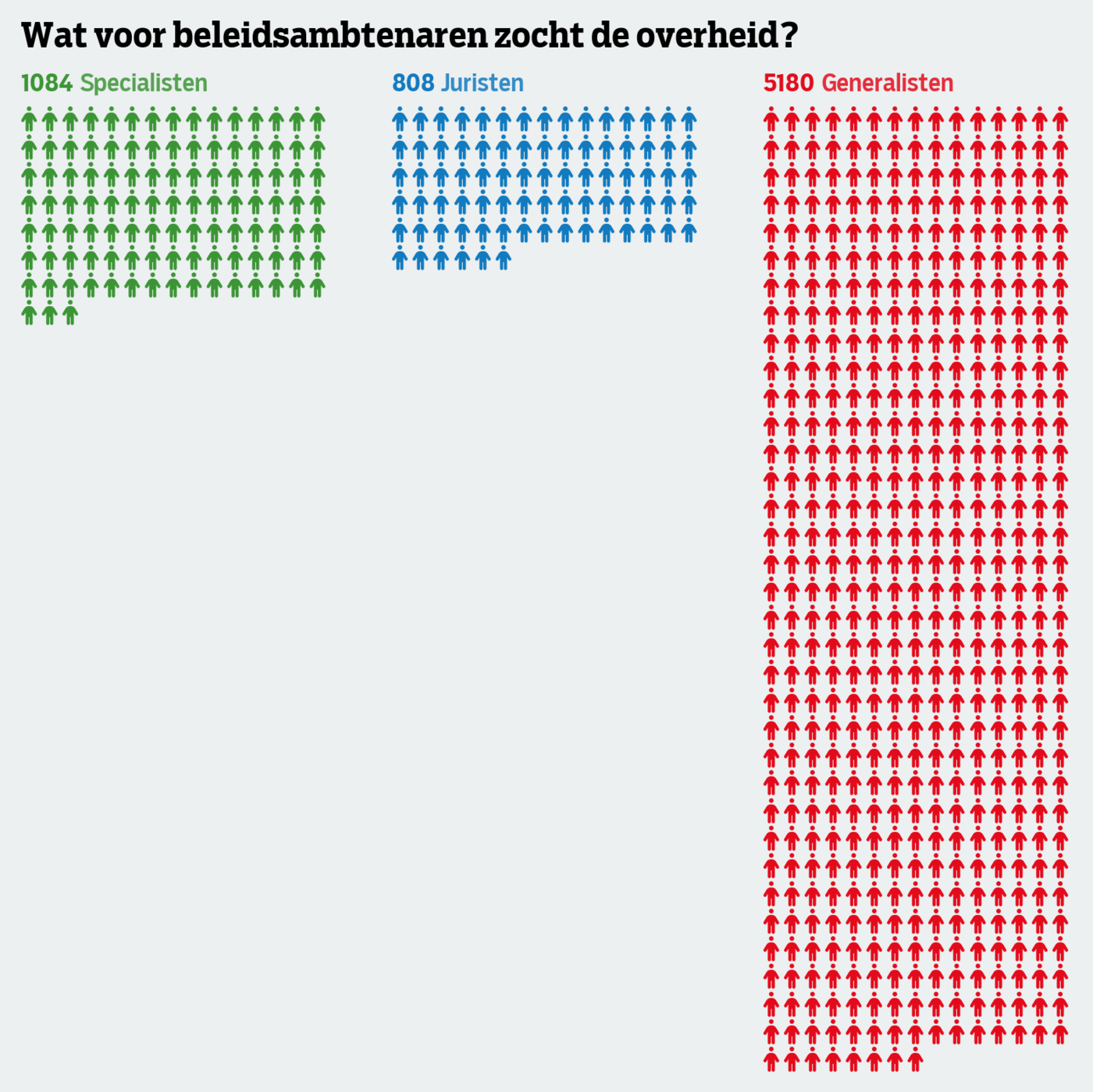
- Geplaatst op
- Uitgelichte Afbeelding
-

Na 35 jaar werken aan digitalisering in de publieke sector geniet ik tijdelijk van een sabbatical. Het grootste deel van mijn loopbaan (tot nu) werkte ik binnen de overheid aan digitalisering. Een