- Geplaatst op
- • Informatievoorziening in de zorg
Waarom ik voor een (vrouwen) quotum ben en waarom je algoritmen moet beoordelen op hun uitkomsten
- Auteur
-
-

- Gebruiker
- Ron Roozendaal
- Bericht van deze auteur
- Bericht van deze auteur
-
Een tijdje terug schreef ik een blog over waarom je algoritmen niet perse moet willen begrijpen. Die blog maakte veel reacties los. Veel daarvan kwam neer op: je snapt toch wel dat vooringenomenheid moet worden bestreden? Mijn antwoord daarop is: ja zeker wel! De vraag is alleen of je daarbij vooral het proces centraal moet stellen of juist de uitkomsten kritisch moet beschouwen.
Een voorbeeld. Als leidinggevende met een achtergrond waarin een dubbeltje niet snel een kwartje zou worden ben ik gespitst op vooringenomenheid in selectieprocessen. Gelukkig is daar steeds meer aandacht voor. Veel van die aandacht gaat naar het proces van selectie zonder vooroordelen (denk aan het weglaten van identificerende gegevens uit brieven en CV’s om de kans op vooringenomenheid te verkleinen).
Maar of een selectieproces zonder vooringenomenheid was kun je ook anders beoordelen, namelijk door de uitkomsten te beschouwen. De vertegenwoordiging van iedereen in de samenleving is best een goede graadmeter. Kort geleden veranderden veel vrouwen op LinkedIn hun naam tijdelijk in Peter. Ze deden dat om aandacht te vragen voor het feit dat er in 2022 nog steeds veel meer mannelijke dan vrouwelijke bestuurders zijn. Sterker nog, er zijn zelfs meer bestuurders die Peter heten dan dat er vrouwelijke bestuurders zijn. De uitkomsten van selectie zijn niet zonder vooroordelen, zo blijkt.
Ik ben er daarom voorstander van om ook eisen te stellen aan de uitkomsten van selectieprocessen. Bijvoorbeeld met een vrouwenquotum, maar eigenlijk breder nog namelijk door eisen te stellen aan inclusie in het algemeen.
Dat is ook de reden dat ik niet perse vind dat je algoritmen moet willen begrijpen. Het zijn de uitkomsten die tellen. Deze moeten zonder vooringenomenheid zijn. Dat is, wat mij betreft, misschien wel het belangrijkst om te blijven toetsen.
In de recent uitgebrachte Leidraad voor kwalitatieve diagnostische en prognostische toepassingen van AI in de zorg heeft dat een belangrijke plek gekregen. Net als bij andere medische interventies geldt ook bij het gebruik van AI in de zorg: het zijn de uitkomsten die tellen. In de leidraad wordt daarom beschreven hoe je de waarden van algoritmen in de zorg onderzoekt met ook aandacht voor bias in de werking.
Bij de externe validatie van het model dient men verder te kijken dan alleen naar de voorspelkracht en medische waarde. Ook evaluatie van eerlijkheid en bias is van groot belang. Ongelijke behandeling ontstaat meestal door een vorm van algoritmische bias
Verschillende vormen van algoritmische bias worden onderscheiden. Het begrippenkader van Suresh & Guttag en de daarin genoemde vormen van bias wordt daarbij toegepast.
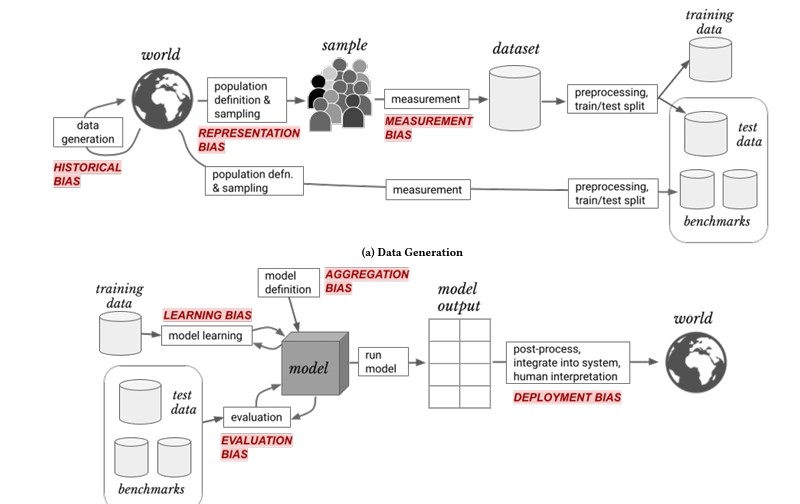
In de leidraad voor kwalitatieve diagnostische en prognostische toepassingen van AI in de zorg worden niet alleen de algoritmen maar vooral de effecten en uitkomsten onderwerp van onderzoek. Zoals de gezondheidsuitkomsten op de lange termijn en op de korte termijn, voor zowel het individu als de populatie.
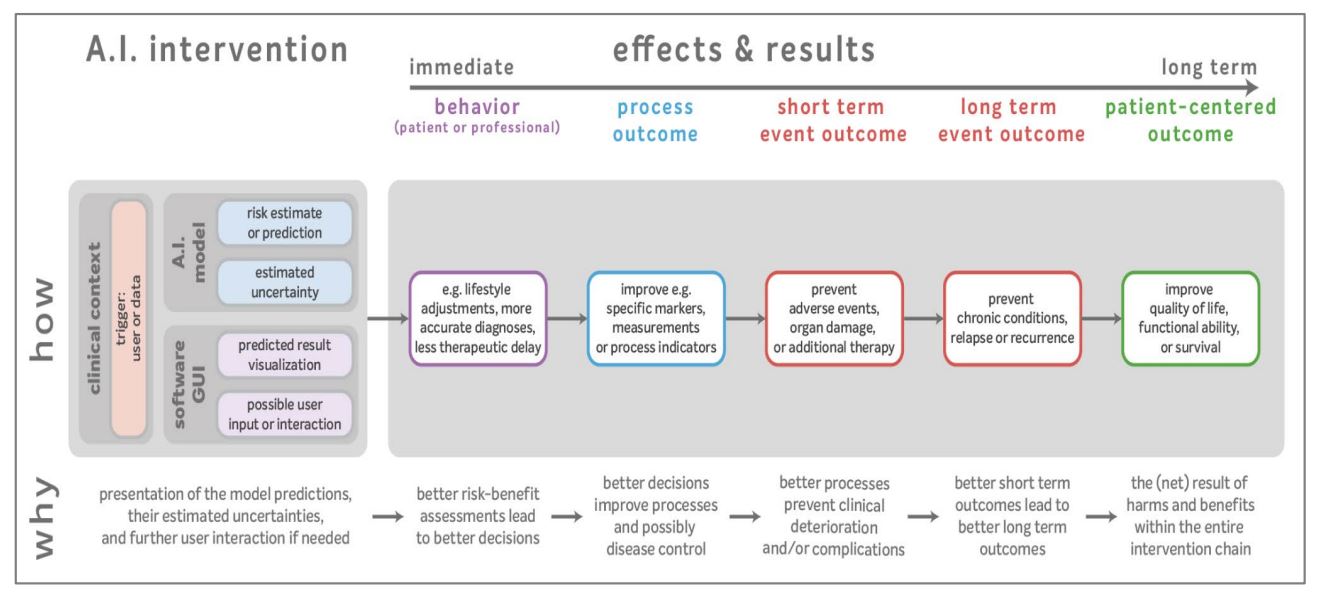 Beoordelen van uitkomsten: dat is zoals in de gezondheidszorg interventies worden beoordeeld. Het voorkomen van ongewenste vooringenomenheid daarin telt daarmee ook. Dat geldt voor handelingen door mensen in de zorg, en ook voor algoritmen.
Beoordelen van uitkomsten: dat is zoals in de gezondheidszorg interventies worden beoordeeld. Het voorkomen van ongewenste vooringenomenheid daarin telt daarmee ook. Dat geldt voor handelingen door mensen in de zorg, en ook voor algoritmen.
Daarom ben ik voorstander van het beoordelen van processen (van zowel mensen als algoritmen) op tenminste hun uitkomsten. En dus, om de cirkel rond te maken, van quota gericht op inclusiviteit bij selectieprocessen.