- Geplaatst op
- Uitgelichte Afbeelding
-
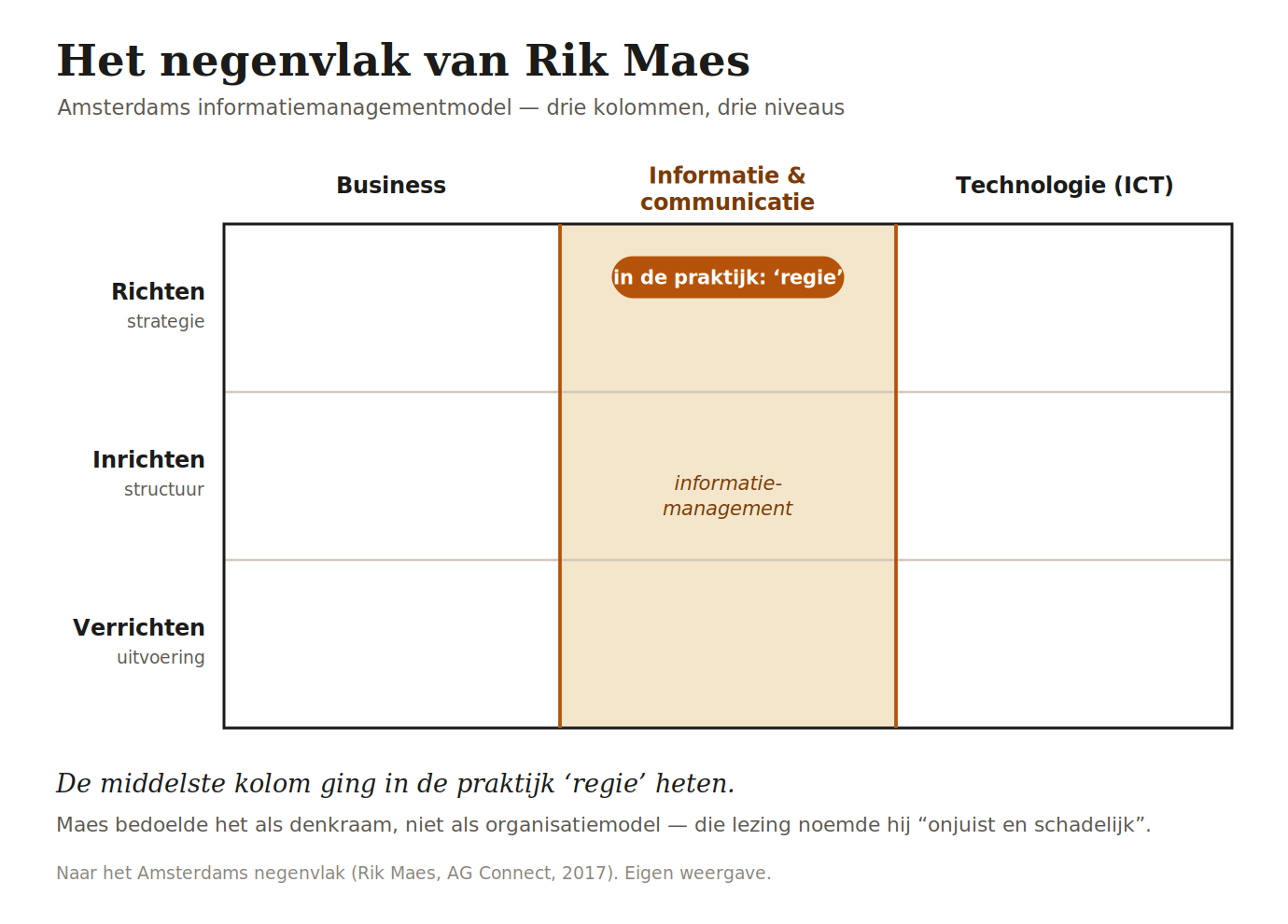
Deze week las ik in iBestuur dat de nieuwe Digitale Dienst "geen centrale uitvoeringsclub" wordt: het kabinet kiest, in lijn met het advies van de NDS-Raad, voor een regie-organisatie. Ik ben blij





.jpg)

