Het is een vraag die in de zorg, maar ook daarbuiten, vaak speelt. Bij het stellen van een diagnose is bijvoorbeeld soms informatie van andere artsen zinvol. Denk aan een oude MRI-scan of een eerdere diagnose. Maar wie maakte die scan ook al weer, hoe lang geleden was dat eigenlijk, is die scan nog beschikbaar? Je kunt natuurlijk een rondje bellen, maar dat is veel werk en niet altijd even doelmatig. Elektronisch de vraag stellen aan alle zorgaanbieders kan ook, maar heeft nog al wat haken en ogen. Wat als een GGZ-instelling die vraag over mij zou stellen aan alle zorgaanbieders, of een verslavingskliniek? Alleen al de vraag stellen geeft meer prijs dan je lief is.
Datzelfde vraagstuk hadden we bij het maken van CoronaCheck. Als ik in de app mijn QR-code aanmaak dan bevraagt de app meerdere bronsystemen op vaccinatie-, test- en herstelgegevens van mij. Op dit moment gaat het om de GGD, het RIVM en ZKVI (het systeem dat gebruikt wordt door ziekenhuizen die bijvoorbeeld huisartsen en ambulancepersoneel uit de eigen regio vaccineren). CoronaCheck doet dat niet door het BSN te versturen, want dat levert het privacyprobleem op dat ook de verslavingskliniek van hiervoor zou hebben. Het pseudoniem van de persoonsgegevens dat wordt verstuurd kan alleen worden gemaakt als de bron ook gegevens over de persoon bevat. Daarmee kunnen de andere bronnen niet herleiden om wie het gaat.
In de DPIA is dat alsvolgt beschreven:
Met name voor de vaccinatiegegevens geldt dat de betrokkenen die de gegevens wil opvragen om een Bewijsmiddel aan te maken niet altijd weet in welke vaccinatieadministratie zijn of haar gegevens zijn opgenomen (omdat de eerste vaccinatie mogelijk in een andere administratie is opgenomen dan de tweede of omdat men niet goed weet onder wiens verantwoordelijkheid de vaccinatie is uitgevoerd). Om toch te kunnen zorgen dat de persoon kan beschikken over een EU DCC en Coronatoegangsbewijs is de volgende oplossing ontwikkeld. Na DigiD verificatie van de persoon wordt door middel van een gepseudonimiseerde bevraging van de relevante administraties, de vaccinatie‐/test‐/herstelgegevens van de gebruiker opgevraagd bij alle (potentieel) relevante partijen.
Met het BSN en van BRP‐gegevens (voornaam, geboortenaam en geboortedatum) wordt een cryptografische hash‐waarde berekend met behulp van het SHA‐256 algoritme. Omdat genoemde invoerdata een zekere mate van voorspelbaarheid heeft, is de maximale entropie van dit deel van de hash‐waarde niet de 256 bits die het SHA‐256 algoritme potentieel biedt, maar is deze gereduceerd tot ongeveer 58 bits in de meest conservatieve schatting, maar effectief waarschijnlijk 70 bits (dit heeft te maken met de structuur van het BSN, hoe uniek achternamen zijn en dat de geboortedata in een maximaal interval van 1906 tot 2021 zullen liggen). Om deze nog relatief lage entropie te adresseren wordt bij de berekening van de hash‐waarde een voor de zorgaanbieder unieke salt gebruikt (ook wel shared secret genoemd) die de entropie voor derden verhoogt evenredig aan de lengte van de salt.
Vooralsnog wordt uitgegaan van een totale entropie (voor derden die niet bekend zijn met de salt) van 384 bits of meer. Dit vormt samen de “UNOMI‐token”.
Ik vind dit een mooie oplossing om ook op andere plekken in de zorg te beproeven. Bijvoorbeeld om mijn Persoonlijke Gezondheidsomgeving te kunnen vullen met al mijn historische gegevens. Zo'n beproeving vergt wel een passende grondslag, want het gaat ook bij een pseudoniem nog steeds om een persoonsgegeven.
Meer weten over de technische oplossing? Die is beschreven op Github.
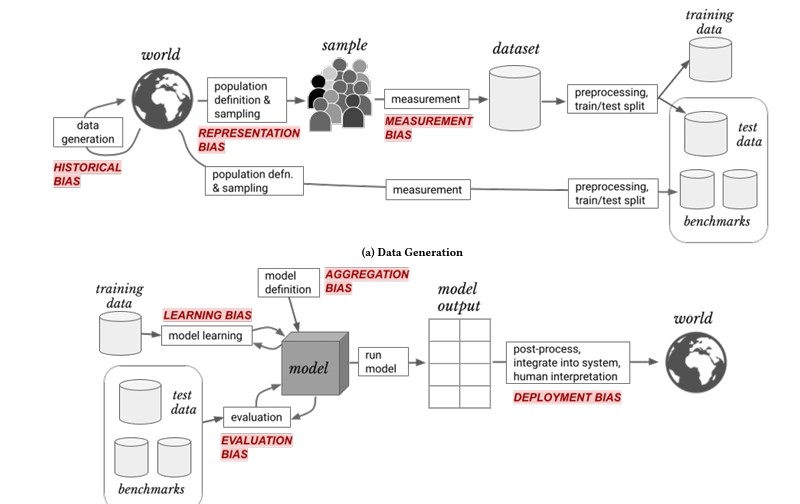
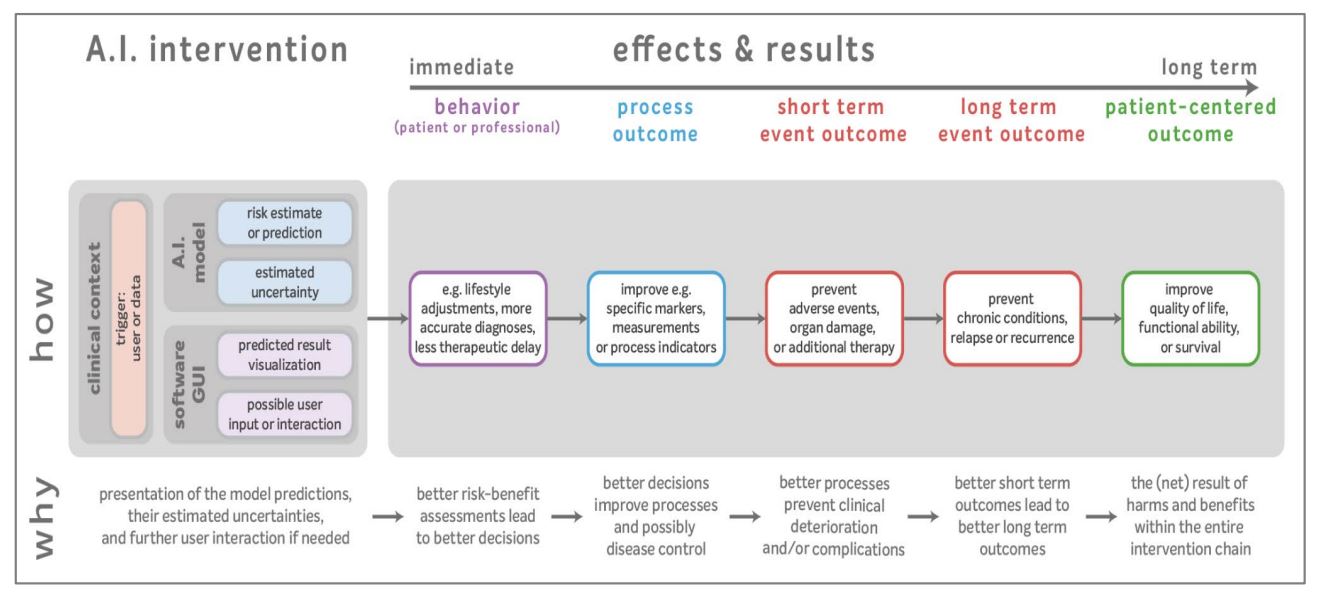 Beoordelen van uitkomsten: dat is zoals in de gezondheidszorg interventies worden beoordeeld. Het voorkomen van ongewenste vooringenomenheid daarin telt daarmee ook. Dat geldt voor handelingen door mensen in de zorg, en ook voor algoritmen.
Beoordelen van uitkomsten: dat is zoals in de gezondheidszorg interventies worden beoordeeld. Het voorkomen van ongewenste vooringenomenheid daarin telt daarmee ook. Dat geldt voor handelingen door mensen in de zorg, en ook voor algoritmen.