Vandaag schreef Follow the Money over de ontwikkeling van een “wallet” door de overheid. Of, zoals zij het noemen, de digitale bewijspas. Ik ben daarbij betrokken, en dus vast bevooroordeeld. Maar twee dingen vallen mij op, en doen me denken aan onderwerpen waarover ik al vaker schreef. Vandaar een nieuwe blog. Over hoe ik zelden nog betaal met een fysieke bankpas. En over dat je toch goed moet afwegen of je in een winkel ook met een app moet willen kunnen aantonen dat je 18+ bent.
Maar eerst die twee dingen die me opvielen. Over waarborgen bij regie op gegevens en over de vlag die de lading niet dekt.
Regie op - en bescherming van - je eigen gegevens
In de zorg wordt het steeds gebruikelijker: je eigen gegevens zelf ook hebben. Om samen te beslissen over jouw behandeling is het nodig om over dezelfde gegevens als je zorgverleners te beschikken. Daarom wordt veel energie gestoken in het toegankelijk maken van de eigen gegevens voor patiënten.
Gegevens- en data-uitwisseling tussen patiënt/cliënt en aanbieder en aanbieders onderling wordt, conform privacywetgeving, verbeterd waarbij uniformiteit noodzakelijk is. Een goed functionerende persoonlijke gezondheidsomgeving (PGO) voor patiënten is het einddoel, aldus het coalitieakkoord.
Aan die emancipatie van mondige patiënten is veel discussie vooraf gegaan. Maar de laatste jaren is het gewoon geworden om over dezelfde gegevens beschikken als je zorgverlener. In de meeste ziekenhuizen kun je het medisch dossier en de laatste uitslagen al inzien voordat je in de spreekkamer zit. En kun je ook die gegevens downloaden en er zelf over beschikken. Daarmee komen gegevens die (als het goed is) goed beschermd bij zorgverleners zijn opgeslagen en die ook juridisch (bijvoorbeeld door het beroepsgeheim) zijn beschermd in handen van onszelf. Wij kunnen daarmee doen wat we willen. En dus, bijvoorbeeld, ze verliezen, per ongeluk delen, of niet meer kunnen aantonen dat ze echt van de eigen zorgverlener komen, over onszelf gaan en niet gewijzigd zijn. Daarom is MedMij ontwikkeld. MedMij is een afsprakenstelsel voor persoonlijke gezondheidsomgevingen dat er voor zorgt dat, ook al is gezondheidsinformatie in het consumentendomein gebracht, mensen erop kunnen vertrouwen dat hun medische informatie klopt, veilig is en vertrouwd gedeeld kan worden. Nederland zet daarbij een stap die internationaal bijzonder is. Informatie wordt aan mensen zelf gegeven, maar er worden tegelijkertijd extra waarborgen aangebracht. Je eigen papieren medische dossier kon je ook al kopiëren en verspreiden. Maar digitalisering maakt dat risico groter, en gaat daarom gepaard met extra bescherming.
Hetzelfde is ook aan het gebeuren op andere domeinen dan de zorg. Bij de overheid, bijvoorbeeld. Onder de noemer ”Regie op gegevens” wordt er aan gewerkt dat wij allemaal de informatie kennen die de overheid over ons heeft, en daarover ook zelf kunnen beschikken. Over een bewijs van ons inkomen bijvoorbeeld, of over onze diploma’s. Gevoelige gegevens, net zoals medische gegevens. Gegevens waar we zelf, ook ik, niet altijd even precies mee omgaan. Want zeg eerlijk: sta jij een hotel toe om een kopie van je paspoort te maken, als ze je anders niet toelaten? Die kopie is bijvoorbeeld handig voor mensen die met jouw identiteit en op jouw naam een telefoonabonnement willen afsluiten. Maar zeg maar eens nee in het hotel.
Het zijn gegevens die we ongemerkt best vaak gebruiken. Om ons inkomen aan te tonen als we een woning huren of kopen, of als we solliciteren naar een functie waarbij een diploma wordt gevraagd. Ook hier geldt: op papier moet je met die gegevens al zorgvuldig omgaan. Maar digitalisering maakt verspreiding en dus ook misbruik makkelijker.
Het artikel waar ik aan het begin naar verwees beschrijft de ontwikkeling van een “voorbeeld wallet”. Een ontwikkeling waarbij de vraag precies dezelfde is als bij persoonlijke gezondheidsomgevingen: als je mensen hun eigen gegevens digitaal geeft, kun je dan extra waarborgen bieden dat die gegevens niet zomaar misbruikt kunnen worden. En kun je er zo voor zorgen dat mensen zelf regie houden over hun gegevens en het gebruik daarvan?
Je eigen gegevens ook digitaal hebben is onvermijdelijk: de meeste mensen verwachten terecht dat de overheid ze vertelt wat ze van ze weet en ook een digitaal afschrift van die gegevens verstrekt. Net als bij medische gegevens vind ik het een goed idee dat we daarbij ook nadenken over waarborgen en bescherming. Ook als die gegevens de overheid verlaten hebben en bij mensen zelf zijn.
De vlag en de lading
In 2011 werd de ontwikkeling van het landelijk EPD gestopt. Waar EPD voor stond weten nog steeds veel mensen: het Elektronisch Patiënten Dossier. Door het gebruik van het woord "dossier" dachten veel mensen dat er één landelijk dossier zou komen, met alle medische gegevens van alle Nederlanders er in. Ik schreef al eerder: dat ene dossier zou er nooit komen. Maar het woord "dossier" had desondanks blijvend veel invloed.
Misschien geldt hetzelfde wel voor woorden die we nu gebruiken in de ontwikkeling naar een persoonlijke digitale kluis voor andere dan medische gegevens. De Europese Commissie heeft voorstellen gedaan voor een dergelijke digitale kluis voor de eigen gegevens die in de hele EU te gebruiken is. Die kluis wordt "wallet" genoemd. Naar analogie van de portemonnee waarin we pasjes bewaren. Een digitale kluis waar je bijvoorbeeld een diploma in kan doen, je rijbewijs of iets anders. Een soort persoonlijke gezondheidsomgeving dus, maar dan voor andere gegevens. Zoals we vliegtickets, bankpassen of toegangskaarten voor een concert in de portemonnee kunnen stoppen maar tegenwoordig ook op de telefoon kunnen bewaren en tonen.
Met de gegevens in zo’n persoonlijke kluis kun je, zo is het idee, online aantonen dat je 18+ bent, in een ziekenhuis in Frankrijk laten zien dat je een zorgverzekering hebt, of in Denemarken als je een auto huurt aantonen dat je een rijbewijs hebt. Het is bedoeld om, in de digitalisering van veel van wat we doen, een veilig en vertrouwde kluis te bieden voor gevoelige gegevens. Dat kun je “elektronische identiteit” noemen, en dan is het moeilijk om te begrijpen wat je bedoelt (ik vind mijn diploma’s niet mijn identiteit). Of, zoals Follow the Money, bewijspas. Dat is een goed gevonden woord, want je bewijst dat je een diploma hebt, bijvoorbeeld. Maar de kluis (of “wallet” dus zoals het ding ook genoemd wordt) is eerder een opslagplek voor bewijspassen. Wat ik daarin op sla is aan mij, en wat ik wil bewijzen ook. Ik heb nog geen goed alternatief helaas. Alle voorstellen zijn dus welkom!
Open gesprek en de hoogste lat
Heb ik dan een heilig geloof in wallets? Wel nee, dat is niet waar het mij omgaat. Ik vind het mijn recht om ook digitaal over de gegevens te beschikken die de overheid van mij heeft. En om die op te slaan op een manier die ik zelf wil. En tegelijkertijd word ik graag ook een beetje beschermd tegen misbruik. Ik betaal tegenwoordig veel vaker met mijn telefoon dan met mijn fysieke bankpas. Het zou zomaar eens kunnen zijn dat over een tijdje fysieke diploma’s iets uit het verleden zijn geworden en we het heel normaal vinden dat we onze opleiding vooral digitaal bewijzen.
Net als bij medische gegevens vind ik het belangrijk dat we bij andere gegevens goed nadenken “in welke digitale samenleving we willen leven”. En dus stilstaan bij de ethische dilemma's, bij de risico’s, bij of we die acceptabel vinden en bij hoe we die beperken. Een beetje (uitstapje) zoals we privacy beschermen. We kunnen bescherming van persoonsgegevens aan “de markt” over laten. Maar zelf ben ik er blij mee dat er door de overheid extra waarborgen zijn gemaakt dat er zorgvuldig met mijn gegevens wordt omgegaan. Ik ben blij met de AVG bijvoorbeeld. Hoe lastig de vragen naar acceptatie van cookies of de privacyverklaringen op websites ook soms zijn.
Terug naar de datakluis. Als we niets doen komen die digitale kluizen er ook, van allerlei bedrijven. Net als bij medische gegevens vind ik het goed om na te denken over de grenzen en eisen daaraan, en over aanvullende waarborgen. Zodat digitalisering ons niet overkomt maar we het samen richting geven. In alle openheid en met alle dilemma’s op tafel.
Wil je, bijvoorbeeld, in een winkel als je alcohol afrekent ook met je telefoon kunnen bewijzen dat je 18+ bent of daar toch altijd een fysiek identiteitsbewijs vereisen. Wat zijn de risico’s van het gebruiken van een digitaal bewijs in de offline wereld, en wat zijn de kansen en risico’s bij online gebruik?
Wellicht kom je tot de conclusie dat extra waarborgen nodig zijn of je sommige dingen echt niet moet willen. En wellicht kom je tot nieuwe technieken die risico’s beperken. Nederland heeft veel ervaring met transparant en open ontwikkelen en ook met digitale datakluizen en online identiteit. Door voorop te lopen in het open bespreken van de dilemma’s, in het ontwikkelen van voorbeelden en het innoveren op techniek kunnen we de lat hoog leggen als het gaat om veiligheid, toegankelijkheid en privacy. En daarmee ook in Europa de toon zetten.
Daarom werk ik mee aan de ontwikkeling van de bewijspas, wallet, datakluis. Om te zorgen dat we waardengedreven digitaliseren. Dat we het niet zomaar “laten gebeuren” maar in alle openheid samen vorm geven aan een digitale samenleving waarin publieke waarden geborgd zijn.
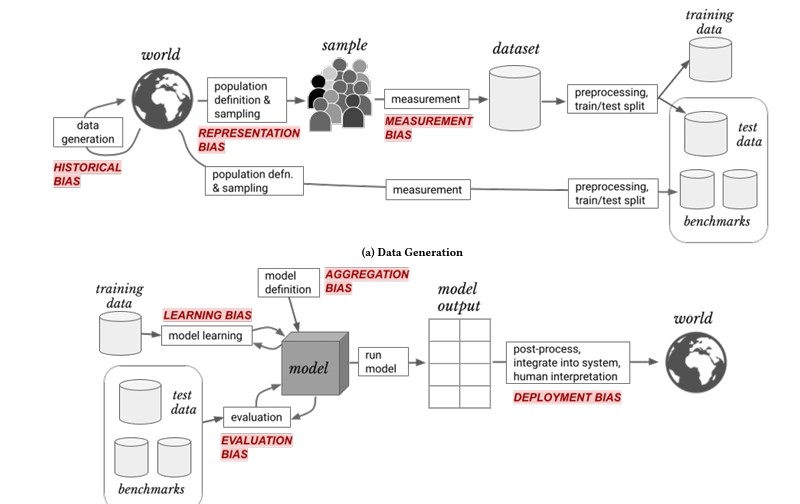
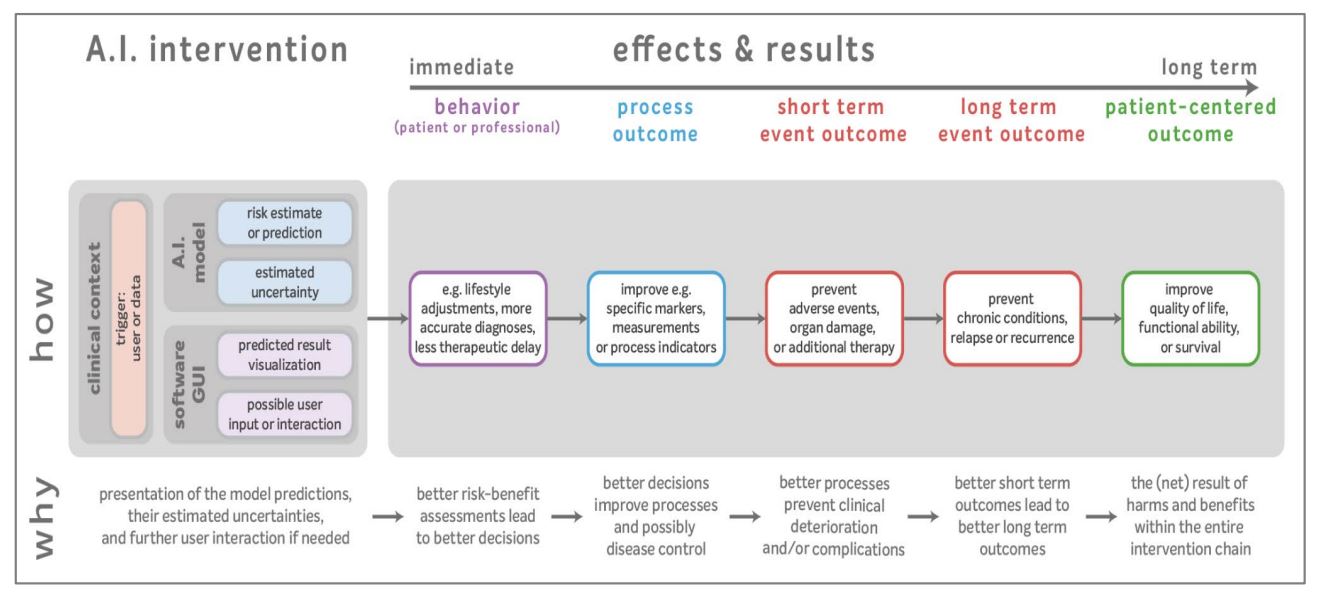 Beoordelen van uitkomsten: dat is zoals in de gezondheidszorg interventies worden beoordeeld. Het voorkomen van ongewenste vooringenomenheid daarin telt daarmee ook. Dat geldt voor handelingen door mensen in de zorg, en ook voor algoritmen.
Beoordelen van uitkomsten: dat is zoals in de gezondheidszorg interventies worden beoordeeld. Het voorkomen van ongewenste vooringenomenheid daarin telt daarmee ook. Dat geldt voor handelingen door mensen in de zorg, en ook voor algoritmen.
